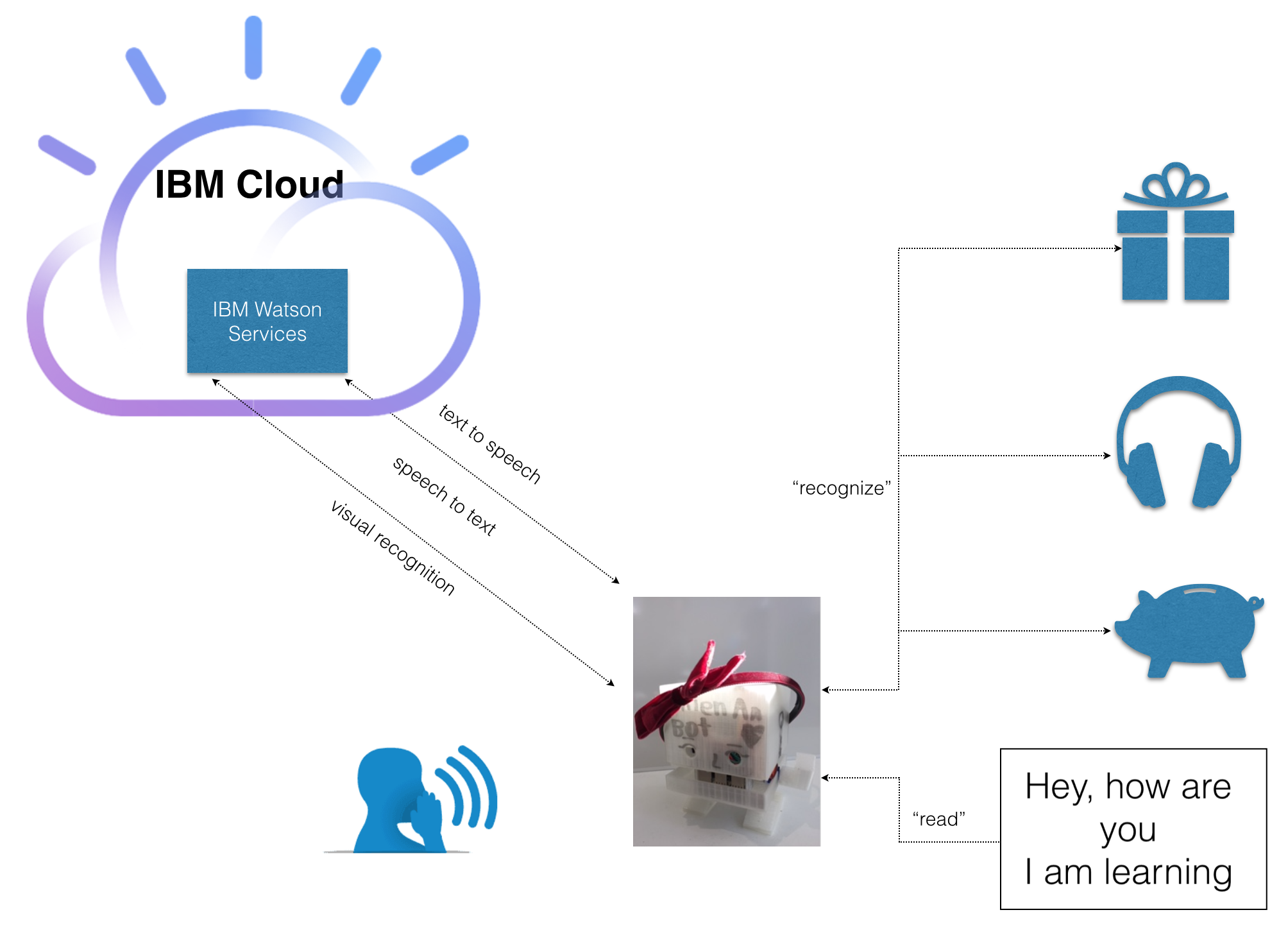
Docker and Kubernetes have been among the most disruptive technologies that dramatically change the IT industry at all level. The technologies really make microservices architecture possible at scale.
Red Hat brings together Docker, Kubernetes and provides a set of APIs to manage those services to form OpenShift Container Platform, aka OCP offering, a completed, end-to-end PaaS for enterprise.
OpenShift has microservices-based architecture of “small”, decoupled services that work together, running on top of a Kubernetes cluster. OpenShift online, OpenShift dedicated and OpenShift container platform are all derived from upstream OKD aka OpenShift origin. The main difference between the upstream OKD and the enterprise OpenShift container platform is the patch schedule. OKD may be updated several times per week whereas OpenShift enterprise is patched and updated when any submitted code changes have passed the stability check check performed by Red Hat QA teams.
Here is how OpenShift looks in diagramming language
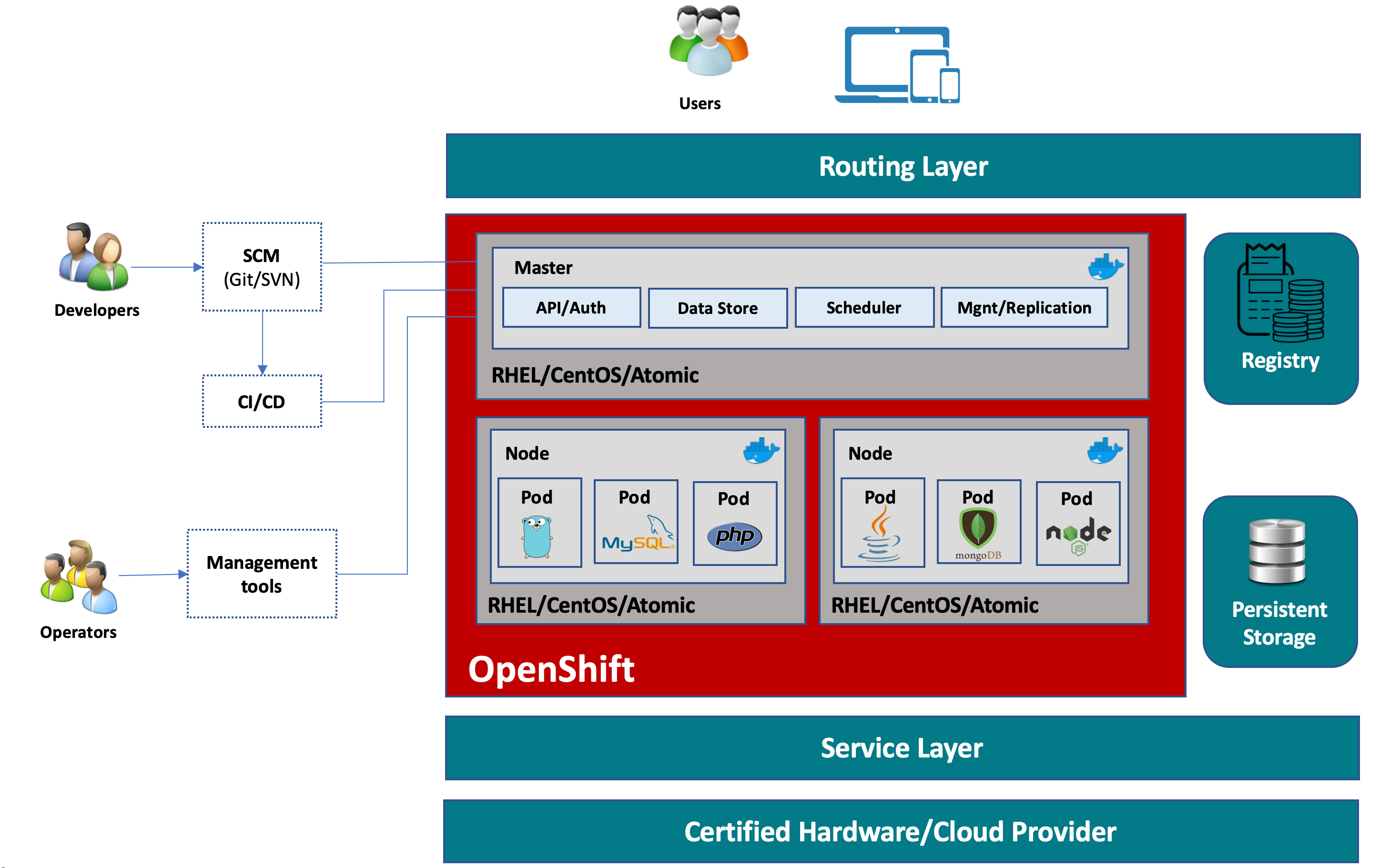
In OpenShift, while Docker provides the abstraction for packing and creating Linux based lightweight container images, Kubernetes provides the cluster management and orchestrating containers on multiple hosts. What OpenShift adds more into that are essentially source code management, builds, and deployments capabilities for developers, management and promotion of Docker images at scale, application management at scale, team and user tracking for organizing large developer organizations, at more.
I’ll discuss how it looks in action in coming next posts …