

In the broader context of software engineering, caching has long been a cornerstone for enhancing performance and efficiency. This concept, equally vital in the field of machine learning, offers a pathway to optimize complex computational processes. Caching, a technique borrowed from traditional software engineering practices, holds the key to expediting data processing and model training in machine learning. Its application transcends merely accelerating tasks; it transforms how we handle large datasets, manage resource-intensive computations, and maintain the resilience of models during extensive training sessions. This exploration delves into how caching, a principle well-established in software development, can be innovatively applied to unleash the full potential of machine learning workflows.
Why caching matters and How does it work
Eliminate redundant work: Imagine preprocessing the same Twitter dataset for sentiment analysis multiple times. Caching lets you preprocess once, store the tokenized and normalized tweets, and reuse them across various sentiment models. It’s like cooking a big meal and having leftovers ready for different dishes!
Manage huge datasets efficiently: If you’re working with a gigantic image dataset for a convolutional neural network, caching allows you to process and store image batches, reducing the time spent reloading them from disk for each epoch.
Recovery from interruptions: Picture training a deep learning model for 36 hours, and your system crashes at hour 34. With caching, your model’s parameters and training state are saved periodically, allowing you to resume training without losing previous progress.
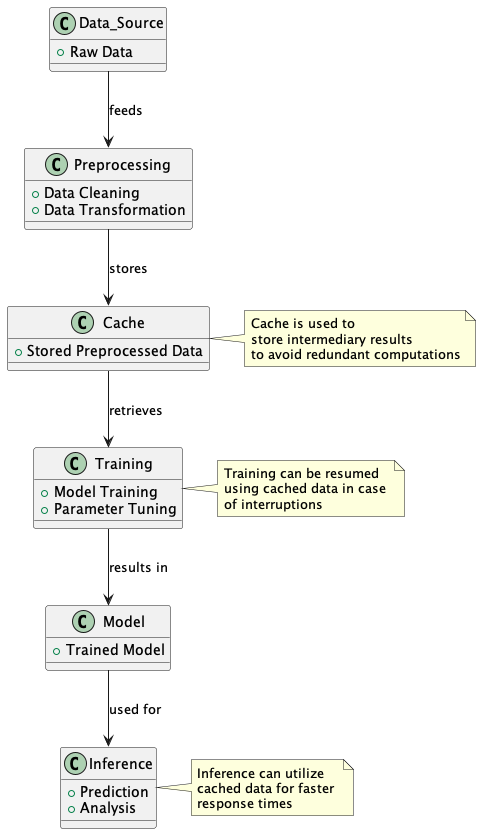
Implementing caching in practice
Each machine learning framework offers unique approaches to caching, tailored to its specific architecture and data handling paradigms. By leveraging these caching mechanisms, machine learning practitioners can significantly enhance the efficiency of their models. Let’s delve into how caching is implemented in popular frameworks like TensorFlow, PyTorch, and Scikit-learn, providing concrete examples to illustrate these concepts in action.
TensorFlow: You can utilize the @tf.function decorator in TensorFlow for caching computations in a model. This decorator transforms your Python functions into graph-executable code, speeding up repetitive operations.
PyTorch: In PyTorch, you can leverage the DataLoader with Dataset for efficient caching. When training a language translation model, use a custom Dataset to load and cache the tokenized sentence pairs, ensuring tokenization is not redundantly performed during each epoch.
Scikit-learn: In Scikit-learn, you can use the Pipeline and memory parameter for caching. For example, in a grid search over a pipeline with scaling, PCA, and a logistic regression classifier, caching the results of scaling and PCA for each training fold avoids unnecessary recalculations.
Choosing what to cache
Data Caching: Storing preprocessed data for faster future analyses or model training. Example: Caching tokenized and normalized text datasets in an NLP pipeline, so you don’t have to re-tokenize each time you train a different sentiment analysis model.
Model Caching: Storing trained model parameters to skip retraining and speed up predictions. Example: Caching a trained convolutional neural network (CNN) for image classification, so subsequent image analyses can use the pre-trained model without starting from scratch.
Result Caching: Caching evaluation metrics to quickly compare model configurations. Example: Storing the accuracy and loss metrics of various deep learning models on a validation dataset, enabling rapid comparison of model performance.
Feature Caching: Saving intermediate features to skip redundant computations during training. Example: In a face recognition system, caching extracted facial features from training images so that feature extraction doesn’t need to be repeated in each training iteration.
Memoization: Memorizing function results to avoid recomputation. Example: Using memoization in a Fibonacci sequence calculation in a data analysis algorithm, where previously computed terms are cached to avoid redundant calculations.
Distributed Caching: Employing distributed caching for efficient collaboration in projects. Example: In a multi-user recommender system project, using a distributed cache to store user profiles and preferences, enabling quick access to this data across the network, thereby enhancing response times for recommendations.
Selecting the right targets: Focus on caching computationally expensive or frequently used processes, such as vectorization in text data processing for NLP applications. This is where caching will have the most impact. Conversely, it’s generally more efficient to avoid caching tasks that are quick to execute or are seldom needed, as the overhead of caching may outweigh its benefits.
Stability vs. Volatility: Cache stable data, such as a fixed training dataset. If your dataset is constantly changing, for example, in the case of real-time stock market data, caching might be less beneficial.
Managing your cache wisely
Sizing the cache: Balance your cache size based on available memory, especially in large-scale data analysis projects.
Optimizing storage: Choose caching formats wisely, considering factors like compression to save disk space.
Keeping cache relevant: Regularly clear cache of outdated models or data, akin to updating your apps for the best performance.
Testing and evaluating cache performance
Verifying effectiveness:
Runtime comparison: Conduct a side-by-side comparison of the runtime, for example, for a recurrent neural network (RNN) with and without cached preprocessed data. In a text generation RNN, time the process of generating text when the model uses a cached dataset of tokenized words versus when it processes raw data each time.
Consistency checks: Ensure the consistency of results when using cached data. It’s crucial that caching does not introduce discrepancies in output. For example, verify that the accuracy of a sentiment analysis model remains consistent whether the data is cached or not.
Scenario-based testing: Test caching effectiveness in different scenarios, such as with varying data sizes or under different system loads. This helps understand caching behavior in real-world conditions.
Quantifying improvements:
Training time analysis: Measure and compare the total training time of a machine learning model with and without caching. For instance, in a large-scale image classification task, record the time it takes to complete training epochs under both conditions.
Resource utilization metrics: Apart from time, assess the impact of caching on resource utilization, such as CPU, GPU, and memory usage. Tools like Python’s cProfile, or the likes, can be instrumental in this analysis.
Speed-up ratios: Calculate the speed-up ratio obtained by caching. This is done by dividing the time taken without caching by the time taken with caching. A speed-up ratio greater than 1 indicates a performance improvement.
Caching, when applied correctly, is a powerful tool in the machine learning toolkit. It’s not just about speed; it’s about making your workflow smarter and more resilient. With these strategies and examples, transform your machine learning projects into more efficient, effective operations.
