In a digital world where enriched content is king, the ability to break language barriers and cultural nuances can crown content creators and give them a global audience. In the meantime, we have been witnessing the profound influence of Artificial Intelligence (AI) on our daily activities. But how can AI help transcend these boundaries, not just in text but in the full communicative spectrum of video—with audio, facial expressions, and body language all conveying meaning?
Something like this video:
Let’s explore an architecture that makes this possible, utilizing open sources only
The Need for Advanced Translation
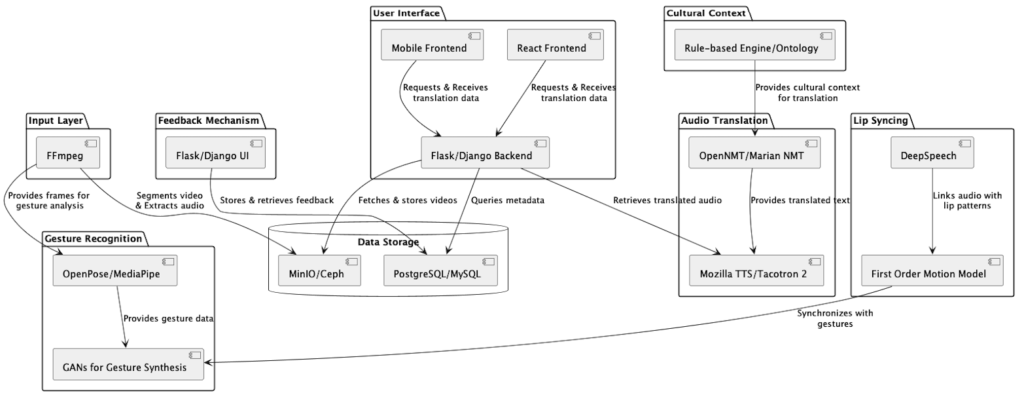
Our children are growing up in a competitive world, not just against each other but against the rising tide of artificial intelligence. To stand out, they must be unique and authentic. This philosophy holds true for content creators in the digital age who seek to differentiate their work and reach across linguistic and cultural divides. Ironically, the tool that empowers this unique human touch could be AI itself. What if we can build an open-source-based system that empowers creators to translate videos, complete with synced audio and body gestures, tailored to every language’s nuances? Here’s a straw-man view of how the system would come together:
Input Layer
Using FFmpeg, the system preprocesses and segments videos into frames, extracts audio streams, and categorizes metadata. This normalized content is then ready for the next layers of processing.
Audio Translation
OpenNMT and Marian NMT take the stage for accurate text translation, followed by Mozilla TTS or Tacotron 2, transforming text back into speech that carries the original emotion and intent, now in a new language.
Gesture Recognition and Synthesis
Using tools like OpenPose or MediaPipe for recognizing human gestures, the system then employs Generative Adversarial Networks (GANs) to synthesize these gestures, ensuring they align with the translated speech in context and cultural relevance.
What about Lip Syncing?
DeepSpeech could be used to analyze the spoken elements, aligning them with lip movements captured from the original video. The First Order Motion Model can be utilized to ensure that these movements are seamlessly synced with the new audio.
Cultural Context Integration
This is a tricky part, but there are tools available that can enable it. A Rule-based Engine informed by Ontology Databases can infuse translations with cultural sensitivity, making not only the words but also the non-verbal, “body-language” part of communication appropriate and relatable.
Feedback Mechanism
Creators can refine translations through an intuitive user interface built on open technologies, for example Flask, Django, etc, feeding back into the system for continuous improvement.
User Interface
A comprehensive React administrative, personalized dashboard augmented with a Mobile Frontend allows creators to manage, customize, and analyze their translations. WebRTC enables real-time streaming for on-the-fly reviews as needed.
Infrastructure & Scalability
Docker and Kubernetes can be used to ensure the system is scalable, deployable, and maintainable without interrupting the service to creators.
Data Storage
In addition to the wide array of cloud storage solutions available, MinIO or Ceph can provide redundant and secure storage for the immense data handled during translation processes.
By integrating these components, we can build a system that doesn’t just translate words, but conveys the creator’s original passion and expression in any language. It’s a future where content can truly be universal, and where AI helps us touch the hearts and minds of a global audience, on the fly.