As an open-source enthusiast, the beauty of dynamic and ever-evolving communities never ceases to amaze me. Despite the comfort and ease of SaaS offerings, there’s always a part of me that wants to dive into the world of open-source, where everyday is an opportunity to connect, learn and contribute.
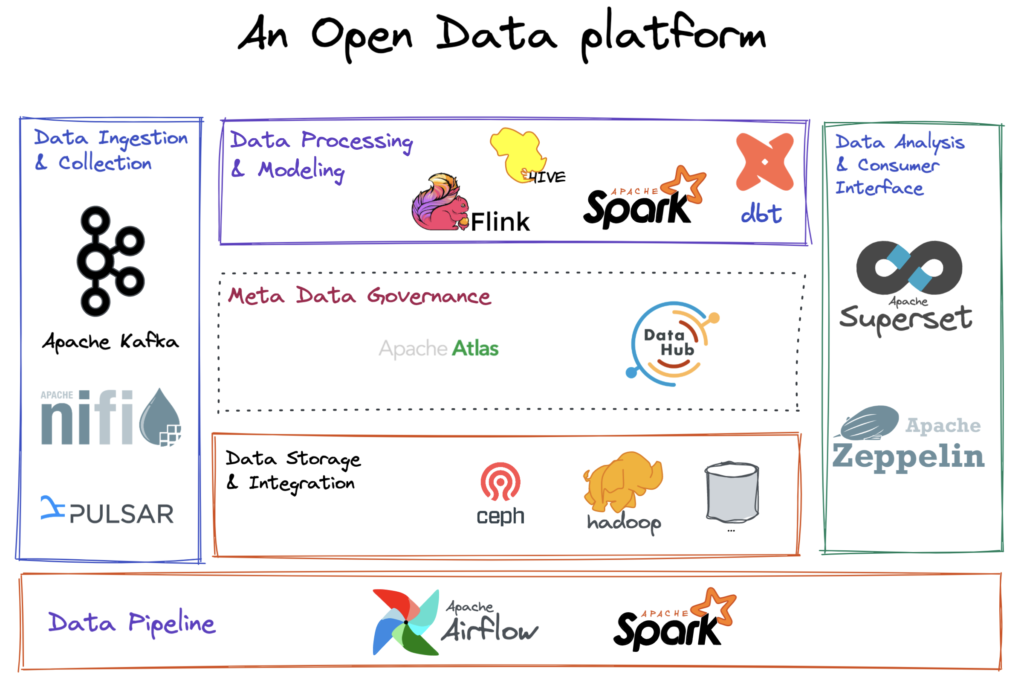
Building a lean and scalable data platform using open-source tools only is now achievable. By selecting the appropriate tools and adopting the right approach, constructing a data platform that meets your organization’s requirements is simply a matter of connecting the necessary existing components. The diagram below shows how the power of open-source tools can be harnessed to create an efficient and streamlined data platform
Example architecture overview of an Open data platform
Some highlighted pillars:
Data Ingestion and Collection: This layer is responsible for collecting and ingesting data from various sources, including files, APIs, databases, and more. Apache Nifi, Apache Pulsa, and Apache Kafka can be used for this purpose.
Data Processing and Modeling: This layer handles the processing, cleaning, transforming, and modeling of the data. Apache Spark, Apache Flink, Apache Hive, and dbt can be utilized in this layer.
Data Storage and Integration: This layer stores data and integrates with various services and components to form the storage foundation. Apache Hadoop HDFS, Ceph and the likes can be utilized here. The almost-unlimited storage capabilities of Cloud can be integrated here of course.
Data Analysis and Consumer Interface: Apache Superset or Apache Zeppelin can be used to analyze the data and generate insights and reports. The data is made accessible through various data visualization and reporting tools, as well as through APIs and data streaming technologies.
Metadata Governance: Apache Atlas or LinkedIn Datahub can be used to implement metadata governance in the data platform architecture. It is responsible for controlling the accuracy, completeness, and consistency of metadata, and ensuring that metadata is stored and managed in a centralized repository.
Data Pipeline: Apache Airflow can be used to manage the data pipeline. It is responsible for scheduling, executing, and monitoring data processing tasks. The pipeline ensures that data is processed and delivered in a timely and accurate manner.
With open-source tools, building a lean and scalable data platform is within reach. Embrace the limitless potential of open-source software and join the ever-growing communities to bring your data platform to the next level. Happy building!
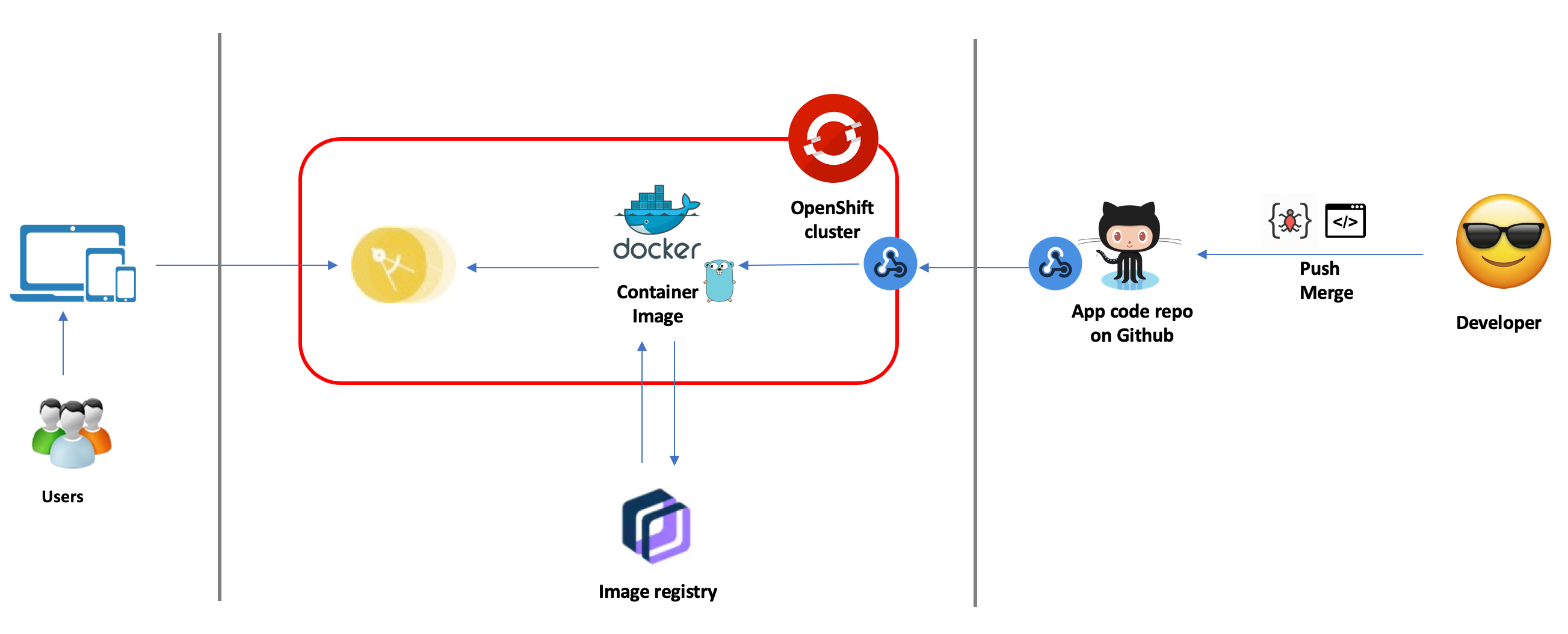
Source-to-Image (S2I) is a framework that makes it easy to write container images that take application source code as an input and produce a new image that runs the assembled application as output. The main advantage of using S2I for building reproducible container images is the ease of use for developers.
As a developer, you don’t need to worry about how your application is being containerized and deployed, you just need to work on your code then deliver to Github. OpenShift will take care of the rest, to make it available to end users.
In this tutorial, we will discuss about how to deploy a Golang web application on OpenShift 4 via source to image (aka s2i) framework. We will also talk about how to enable CI/CD using webhook
OpenShift cli client (aka oc) (run $ brew update && brew install openshift-cli on your Mac terminal
The app
The example application used in this tutorial is a simple Go web app that has a menu to navigate among different pages. The Register page is an html form for the user to submit a name, then the Go server code handles the request and sends the name back for displaying on the page. The app covers how to work with templates in Go.
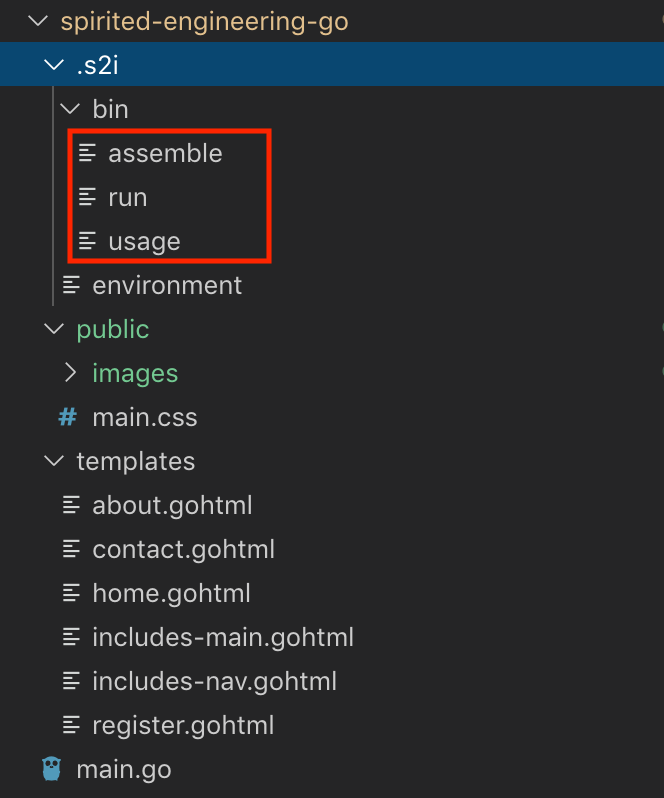
Here is the structure of the code
Code structure
As required by s2i framework, we need to provide assemble and run scripts as minimum to instruct how the code is built and how the built code is executed
assemble script:
#!/bin/bash
set -e
echo "---> Preparing source..."
mkdir -p $S2I_DESTINATION
cd $S2I_DESTINATION
cp -r /tmp/src/* $S2I_DESTINATION/
go build -o /opt/app-root/goexec .
run script:
#!/bin/bash -e
cd $S2I_DESTINATION
/opt/app-root/goexec
Notice that you can put all environment variables necessary for the scripts in the environment file placed in .s2i directory
You can fork the code from here to your git and modify based on your needs: https://github.com/dnguyenv/spirited-engineering-go.git
$ oc get routes
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
spirited-engineering-go spirited-engineering-go-spirited-engineering.apps.se.os.fyre.se.com spirited-engineering-go 8080 edge None
You now can access your app from a browser with this url (HOST/PORT value in the output of oc get routes): https://spirited-engineering-go-spirited-engineering.apps.se.os.fyre.se.com
Here is what you may see from this Go web application example:
Running example application
Enable CI/CD
Now you have the application deployed from your source code on Github all the way to your OpenShift cluster. Lets do 1 step further to make the application deployed automatically whenever you’ve pushed changes to the code on Github. There are different ways to do that but in this example, I’ll walk you through how to do it with webhook
Get the webhook endpoint of the app
Assuming you’re still logged into your OpenShift cluster, run this command to get the webhook endpoint of the app
$ oc describe bc/<your-build-config>
The endpoint will show how under Webhook GitHub section. You can grep the URL against the output
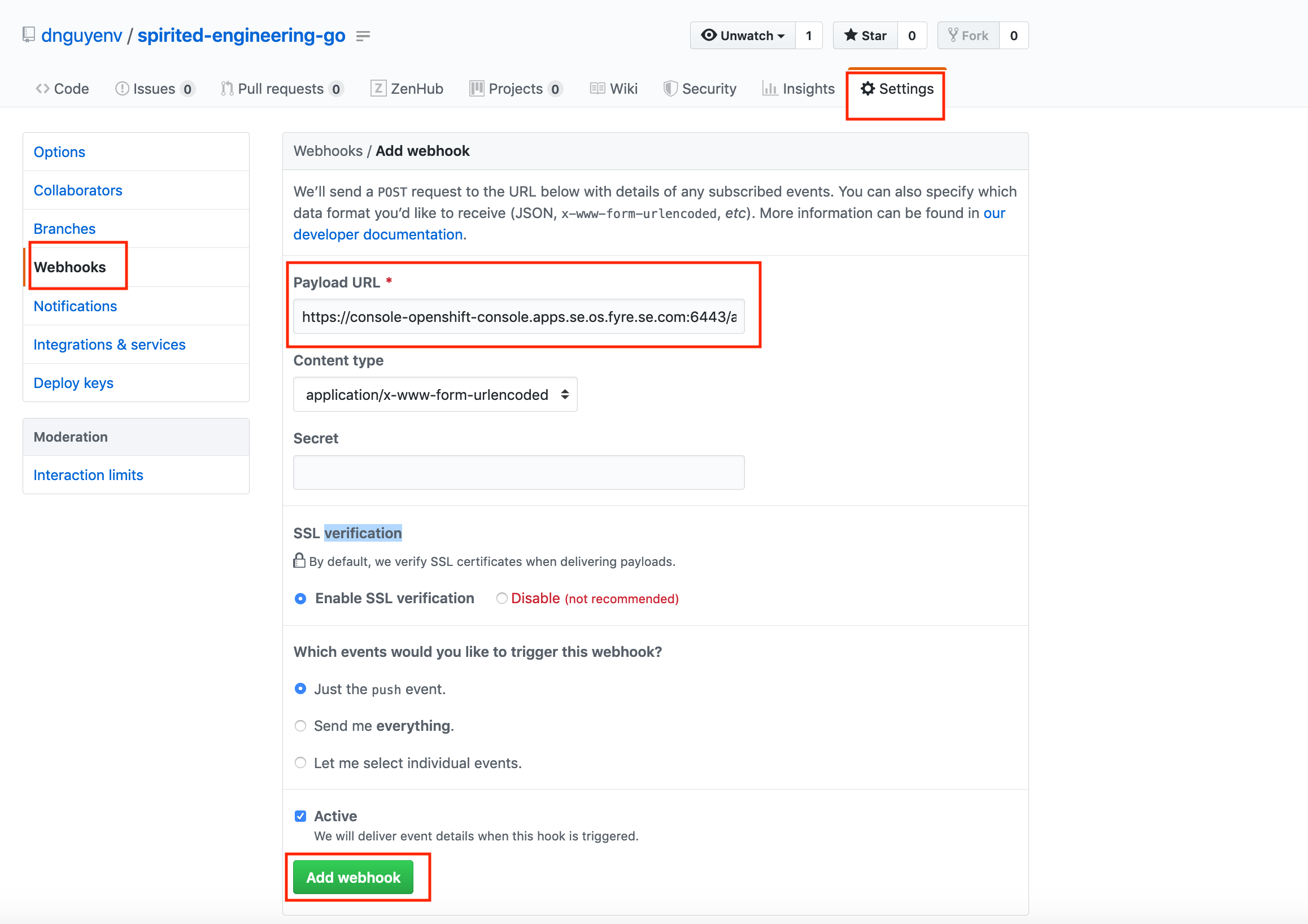
Once you have the webhook endpoint, you now can create a github webhook on your source code repository by going to https://github.com/<your-github-id>/<your-repo>/settings/hooks (example: https://github.com/dnguyenv/spirited-engineering-go/settings/hooks)
Something like this:
Webhook
Now, whenever you push (or merge) any changes into your repository, the webook will send a payload to OpenShift to trigger a build and the changes will be packaged into container(s), deployed and serve the end users.