
As an open-source enthusiast, the beauty of dynamic and ever-evolving communities never ceases to amaze me. Despite the comfort and ease of SaaS offerings, there’s always a part of me that wants to dive into the world of open-source, where everyday is an opportunity to connect, learn and contribute.
Building a lean and scalable data platform using open-source tools only is now achievable. By selecting the appropriate tools and adopting the right approach, constructing a data platform that meets your organization’s requirements is simply a matter of connecting the necessary existing components. The diagram below shows how the power of open-source tools can be harnessed to create an efficient and streamlined data platform
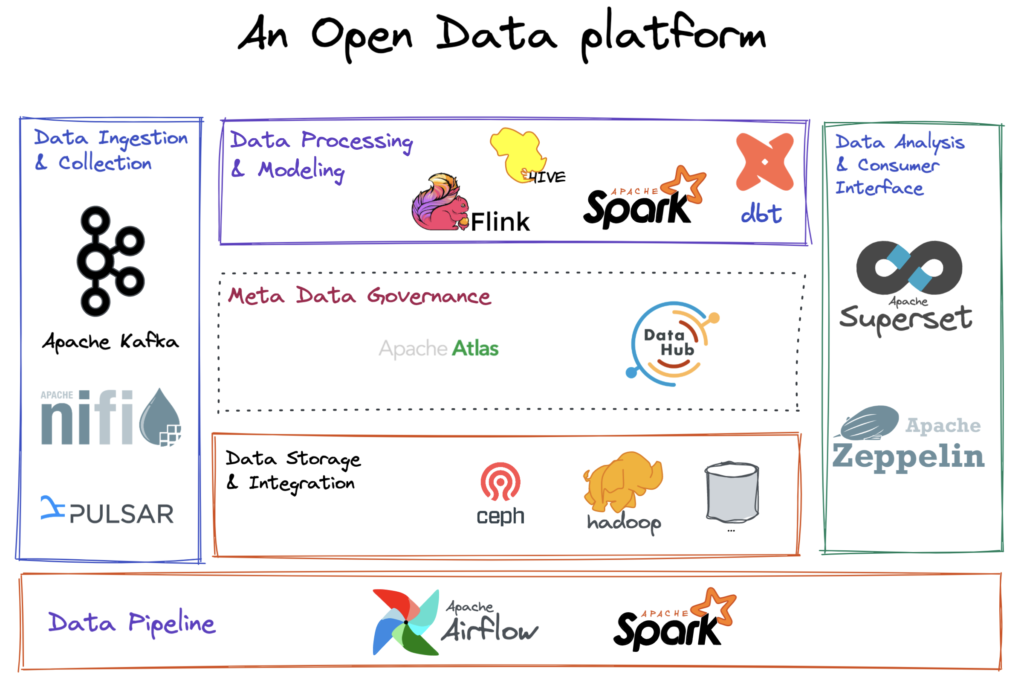
Some highlighted pillars:
Data Ingestion and Collection: This layer is responsible for collecting and ingesting data from various sources, including files, APIs, databases, and more. Apache Nifi, Apache Pulsa, and Apache Kafka can be used for this purpose.
Data Processing and Modeling: This layer handles the processing, cleaning, transforming, and modeling of the data. Apache Spark, Apache Flink, Apache Hive, and dbt can be utilized in this layer.
Data Storage and Integration: This layer stores data and integrates with various services and components to form the storage foundation. Apache Hadoop HDFS, Ceph and the likes can be utilized here. The almost-unlimited storage capabilities of Cloud can be integrated here of course.
Data Analysis and Consumer Interface: Apache Superset or Apache Zeppelin can be used to analyze the data and generate insights and reports. The data is made accessible through various data visualization and reporting tools, as well as through APIs and data streaming technologies.
Metadata Governance: Apache Atlas or LinkedIn Datahub can be used to implement metadata governance in the data platform architecture. It is responsible for controlling the accuracy, completeness, and consistency of metadata, and ensuring that metadata is stored and managed in a centralized repository.
Data Pipeline: Apache Airflow can be used to manage the data pipeline. It is responsible for scheduling, executing, and monitoring data processing tasks. The pipeline ensures that data is processed and delivered in a timely and accurate manner.
With open-source tools, building a lean and scalable data platform is within reach. Embrace the limitless potential of open-source software and join the ever-growing communities to bring your data platform to the next level. Happy building!
