We are all in this together. Whoever they are, keep them in our thoughts and prayers.
“Don’t forget to sing in the lifeboats“
Tears in heaven by Eric Clapton

The spirit of engineering and creation
We are all in this together. Whoever they are, keep them in our thoughts and prayers.
“Don’t forget to sing in the lifeboats“
Tears in heaven by Eric Clapton
Lets say you have a lot of data and you have a team of data scientists working very hard on their AI/ML initiatives to get valuable insights out of the data in order to help driving your business decisions. You want to offer your data scientists the same experience that software developers have in a native cloud environment where they enjoy the flexibility, scalability and tons of other cloud advantages to get their things done faster?
Lots of options available nowadays, and this post walks you through 1 of them using OpenShift 4 and Red Hat Open Data Hub
Architecture over view of the example:
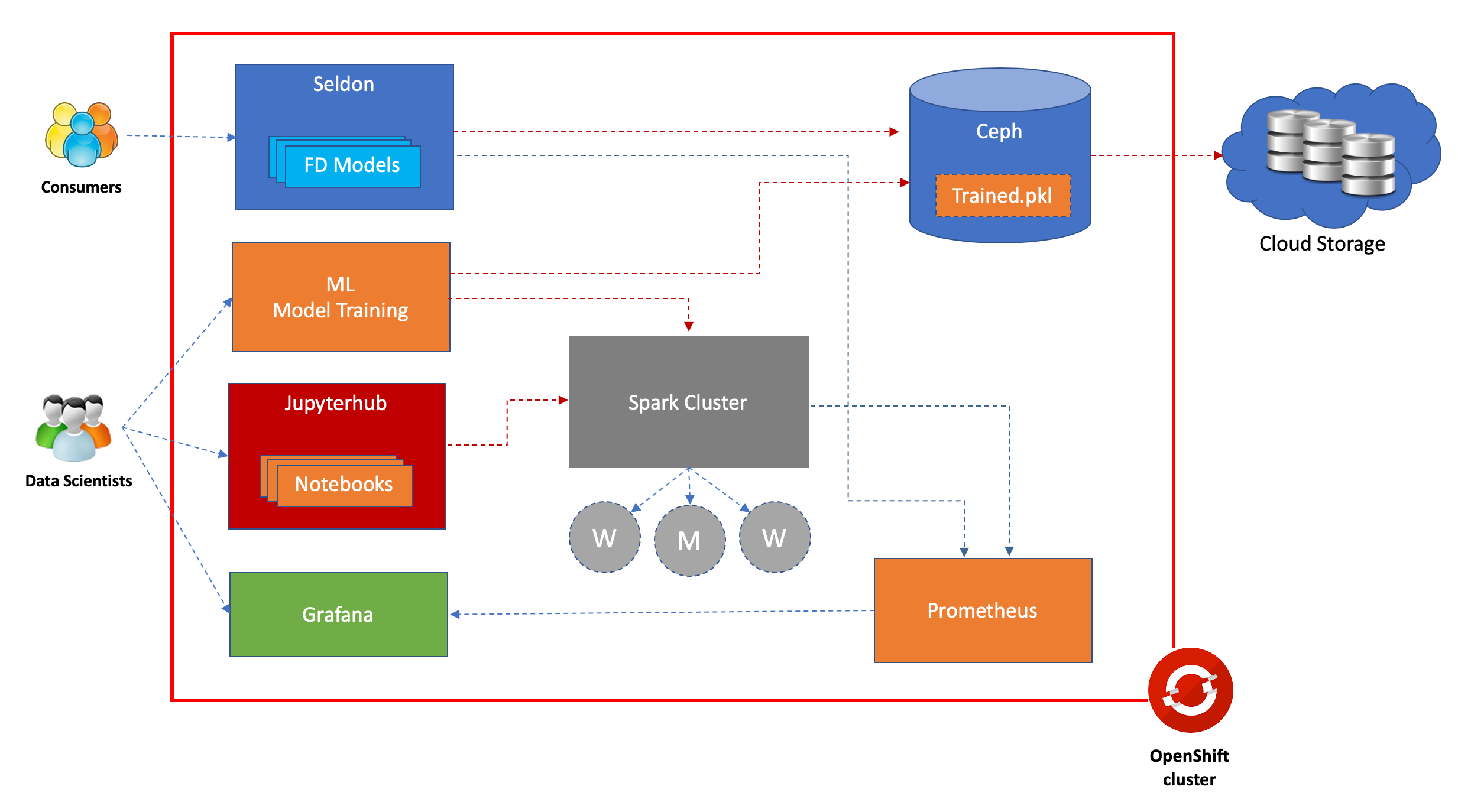
Data exploration and model development can be performed in Jupyter notebooks using Spark for ETL and different ML frameworks for exploring model options
After data exploration and algorithm, model selection, the training activities can be fully performed and resulting trained artifacts can be saved into Ceph
Once the model is available on Ceph, Seldon will help to extract it and serve end consumers
All model development lifecyle can be automated by utilizing variety of available tools or frameworks in Red Hat ecosystem.
Performance of the models can be monitored using Prometheus and Grafana
Prerequisites:
Steps to spin up your environment
Installing Object Storage
We use Rook operator to install Ceph. Make sure you have cluster’s admin credentials
Clone this git repository
$ git clone https://github.com/dnguyenv/aiops-pipeline.git $ cd aiops-pipeline/scripts
scripts folder contains scripts and configuration to install the open data hub operator. These environment variables need to be set before running the commands:
export OCP_ADMIN_USER=export OCP_ADMIN_PASS= export OCP_API_ENDPOINT=
Then login:
oc login -u $OCP_ADMIN_USER -p $OCP_ADMIN_PASS --server $OCP_API_ENDPOINT
Deploy Rook operator:
oc apply -f deploy/storage/scc.yaml
oc apply -f deploy/storage/operator.yaml
Check to make sure that all the pods are running in rook-ceph-system
dunguyen-mac:aiops-pipeline duynguyen$ oc get pods -n rook-ceph-system
NAME READY STATUS RESTARTS AGE
rook-ceph-agent-dsdbv 1/1 Running 0 6h24m
rook-ceph-agent-p77j5 1/1 Running 0 6h24m
rook-ceph-agent-trd2q 1/1 Running 0 6h24m
rook-ceph-operator-574bdfd84d-mcv4g 1/1 Running 0 6h24m
rook-discover-6qhwb 1/1 Running 0 6h24m
rook-discover-8mxbq 1/1 Running 0 6h24m
rook-discover-j869s 1/1 Running 0 6h24m
Once the operator is ready, go ahead and create a Ceph cluster and Ceph object service.
oc apply -f deploy/storage/cluster.yaml
oc apply -f deploy/storage/toolbox.yaml
oc apply -f deploy/storage/object.yaml
Check to make sure all the pods are running in rook-ceph namespace before proceeding
dunguyen-mac:aiops-pipeline duynguyen$ oc get pods -n rook-ceph
NAME READY STATUS RESTARTS AGE
rook-ceph-mgr-a-59f5b66c5f-gj4vc 1/1 Running 0 6h23m
rook-ceph-mon-a-658b6d7794-rh44b 1/1 Running 0 6h24m
rook-ceph-mon-b-bd7f46bd7-9khh7 1/1 Running 0 6h24m
rook-ceph-mon-c-8676f9749-4l6h7 1/1 Running 0 6h24m
rook-ceph-osd-0-57885dbb9-vkjvb 1/1 Running 0 6h23m
rook-ceph-osd-1-5bfcd5d7bb-mzm5q 1/1 Running 0 6h23m
rook-ceph-osd-2-6d4467d788-zdtvt 1/1 Running 0 6h23m
rook-ceph-osd-prepare-ip-10-0-128-169-vhdtx 0/2 Completed 0 6h23m
rook-ceph-osd-prepare-ip-10-0-132-95-7hkq9 0/2 Completed 0 6h23m
rook-ceph-osd-prepare-ip-10-0-141-25-77dhg 0/2 Completed 0 6h23m
rook-ceph-rgw-my-store-58c694cd5b-22zln 1/1 Running 0 6h22m
rook-ceph-tools-78bddc766-v6cv2 1/1 Running 0 6h24m
Now create a set of cloud storage credentials. The resulting credentials will be stored in a secret under the rook-ceph namespace.
oc apply -f deploy/storage/object-user.yaml
Create a route to the rook service. To do that, first find out what is the service name
dunguyen-mac:aiops-pipeline duynguyen$ oc get svc -n rook-ceph
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr ClusterIP 172.30.152.104 9283/TCP 6h27m
rook-ceph-mgr-dashboard ClusterIP 172.30.187.37 8443/TCP 6h27m
rook-ceph-mon-a ClusterIP 172.30.134.112 6790/TCP 6h29m
rook-ceph-mon-b ClusterIP 172.30.158.145 6790/TCP 6h28m
rook-ceph-mon-c ClusterIP 172.30.59.178 6790/TCP 6h28m
rook-ceph-rgw-my-store ClusterIP 172.30.166.74 8000/TCP 6h27m
And then expose it to make the route:
oc expose service rook-ceph-rgw-my-store -l name=my-route --name=spiritedengineering -n rook-ceph
Install the ML pipeline components
Create a new project to contain the pipeline components
oc new-project demo
In order to access the Ceph cluster from other namespace, will need to copy the secret to whichever namespace is running the applications you want to
interact with the object store
For example, you want to use it from demo namespace:
oc get secret -n rook-ceph rook-ceph-object-user-my-store-odh-user --export -o yaml | oc apply -n demo -f-
Before running the installation script, make changes to scripts/deploy/crds/aiops_odh_cr.yaml accordingly to to enable/disable pipeline components as needed.
Deploy the Open data hub custom resource
oc apply -f deploy/crds/aiops_odh_crd.yaml -n demo
Create the RBAC policy for the service account the operator will run as
oc apply -f deploy/service_account.yaml
oc apply -f deploy/role.yaml
oc apply -f deploy/role_binding.yaml
oc adm policy add-role-to-user admin -z opendatahub-operator
Deploy the operator image into the demo project
oc apply -f deploy/operator.yaml
Now deploy the custom resource for open data hub
oc apply -f deploy/crds/aiops_odh_cr.yaml
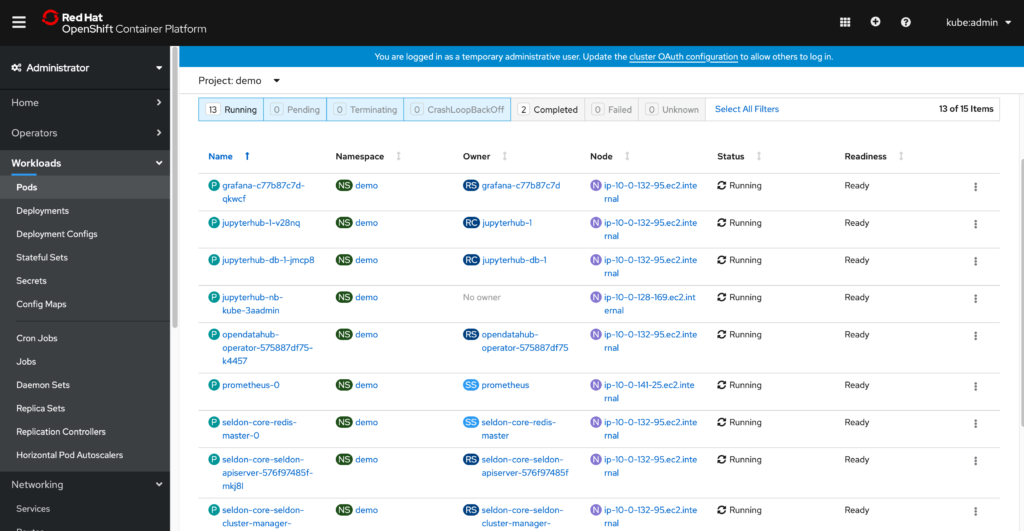
To check if the installation is successful
dunguyen-mac:aiops-pipeline duynguyen$ oc get pods -n demo
NAME READY STATUS RESTARTS AGE
grafana-c77b87c7d-qkwcf 2/2 Running 0 4h33m
jupyterhub-1-deploy 0/1 Completed 0 4h34m
jupyterhub-1-v28nq 1/1 Running 0 4h33m
jupyterhub-db-1-deploy 0/1 Completed 0 4h34m
jupyterhub-db-1-jmcp8 1/1 Running 0 4h34m
jupyterhub-nb-kube-3aadmin 2/2 Running 0 4h32m
opendatahub-operator-575887df75-k4457 1/1 Running 0 4h36m
prometheus-0 4/4 Running 0 4h33m
seldon-core-redis-master-0 1/1 Running 0 4h33m
seldon-core-seldon-apiserver-576f97485f-mkj8l 1/1 Running 0 4h33m
seldon-core-seldon-cluster-manager-b65f8d94-vvm6c 1/1 Running 0 4h33m
spark-cluster-kube-admin-m-pg4zc 1/1 Running 0 4h33m
spark-cluster-kube-admin-w-46z6h 1/1 Running 0 4h33m
spark-cluster-kube-admin-w-zpr9c 1/1 Running 0 4h33m
spark-operator-68f98d85c4-tqrzf 1/1 Running 0 4h33m
Now you are good to utilize the infrastructure as the development environment for your ML initiatives
To access the Jupyterhub and work with your notebooks, you will need to know its endpoint. That can be done by
oc get routes -n demo
And grasp the HOST/PORT value in the returned list accordingly to the jupyterhub route
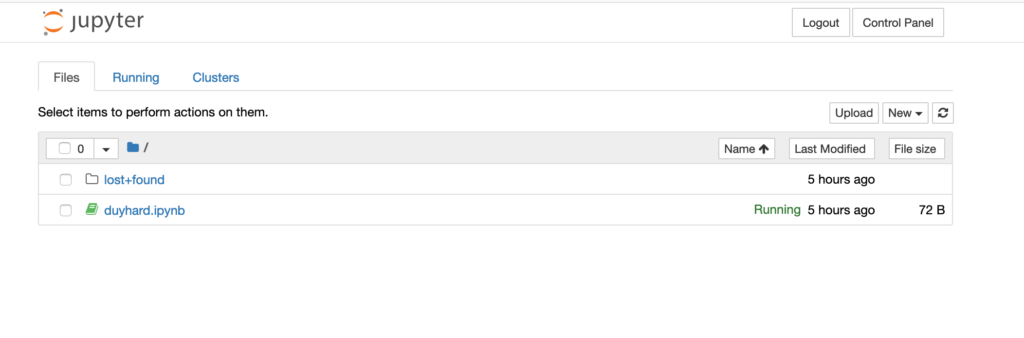
Using that endpoint, you can spawn up a Spark cluster to use for your ML initiatives. Each user will have a dedicated cluster launched as a set of container.
Once the user logs out, the cluster will be terminated.