Generative AI, including exciting machine learning innovation like Generative Adversarial Networks (GANs), is revolutionizing the way we think about data, algorithms, and artificial intelligence in general. To harness its full potential in your use cases, you’ll need a robust data infrastructure. Fortunately, the open-source community provides a plethora of tools to build a solid foundation, ensuring scalability and efficiency without burning a big hole in your pocket. In this post, lets discuss a light weight architecture utilizing open source only components to build your solution:
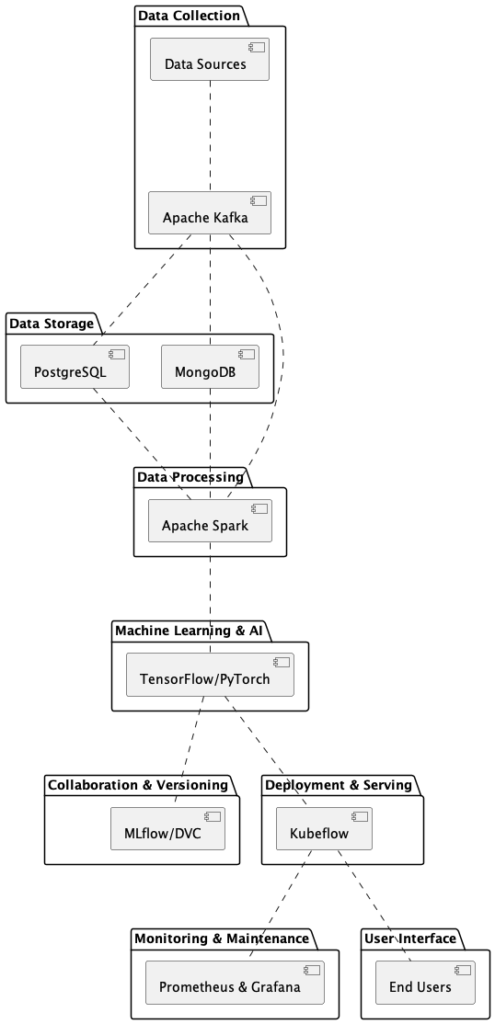
Data Collection and Storage
Apache Kafka: As a distributed streaming platform, Kafka is indispensable for real-time data ingestion. With the ability to handle high throughput from varied data sources, it acts as the primary data artery for your architecture.
PostgreSQL: This object-relational database system is not just robust and performant but also extensible, may help to future-proof your data storage layer. When dealing with structured data, PostgreSQL stands out with its flexibility and performance.
MongoDB: In the realm of NoSQL databases, MongoDB is good option to have. It’s designed for unstructured or semi-structured data, providing high availability and easy scalability.
Data Processing and Analysis
Apache Spark: When you’re grappling with vast datasets, Spark is your knight in shining armor. As a unified analytics engine, it simplifies large-scale data processing. Furthermore, its ability to integrate with databases like PostgreSQL, MongoDB, and other sources, covers almost all over your data preprocessing needs, with high performance and flexibility.
Machine Learning & Generative AI
TensorFlow and PyTorch: The poster children of deep learning, these libraries are comprehensive and backed by massive communities. Their extensive toolkits are perfect for crafting generative AI models, including the popular GANs.
Keras: A high-level neural networks API which can run on top of TensorFlow, making deep learning model creation even more intuitive.
Scikit-learn: Beyond deep learning, traditional machine learning algorithms have their place. Scikit-learn offers a vast array of such algorithms ready to go with minimum warming up effort.
Collaboration, Versioning & Lifecycle Management
MLflow: As AI projects grow, tracking experiments and results can get chaotic. MLflow steps in by ensuring reproducibility and facilitating collaboration among data scientists.
DVC: Think of it as Git, but tailored for data. DVC elegantly tracks data changes, making data versioning and experimentation transparent and simple.
Deployment, Serving, and Scaling
Kubeflow: Deployment can be daunting, especially at scale. Kubeflow, designed to run on Kubernetes, may help to ensure your generative AI models are served efficiently, with the added advantage of scalability.
Monitoring & Maintenance
Prometheus & Grafana: In the ever-evolving landscape of AI, monitoring system health and model performance is a must. With Prometheus for monitoring and Grafana for visualization, you’re a step ahead in ensuring optimal performance.
By strategically piecing together these open-source solutions, organizations can establish a formidable data infrastructure tailor-made for generative AI, promoting innovation while ensuring cost-effectiveness.
Below is a visual representation of how the various open-source components may come together to form a basic architecture that may help you ready to roll quickly