As an open-source enthusiast, the beauty of dynamic and ever-evolving communities never ceases to amaze me. Despite the comfort and ease of SaaS offerings, there’s always a part of me that wants to dive into the world of open-source, where everyday is an opportunity to connect, learn and contribute.
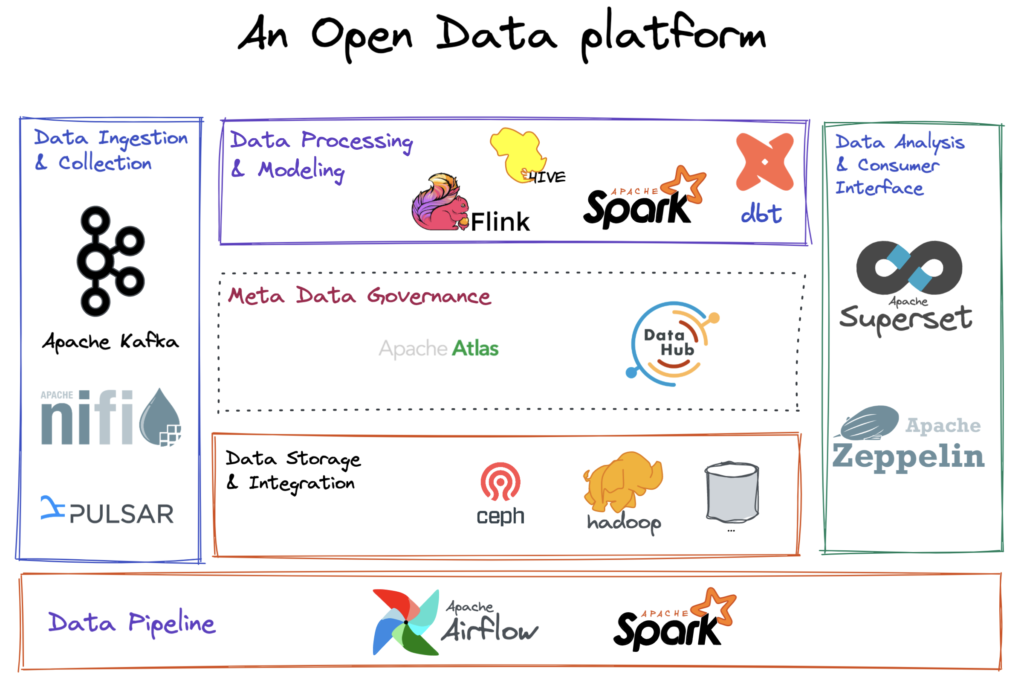
Building a lean and scalable data platform using open-source tools only is now achievable. By selecting the appropriate tools and adopting the right approach, constructing a data platform that meets your organization’s requirements is simply a matter of connecting the necessary existing components. The diagram below shows how the power of open-source tools can be harnessed to create an efficient and streamlined data platform
Example architecture overview of an Open data platform
Some highlighted pillars:
Data Ingestion and Collection: This layer is responsible for collecting and ingesting data from various sources, including files, APIs, databases, and more. Apache Nifi, Apache Pulsa, and Apache Kafka can be used for this purpose.
Data Processing and Modeling: This layer handles the processing, cleaning, transforming, and modeling of the data. Apache Spark, Apache Flink, Apache Hive, and dbt can be utilized in this layer.
Data Storage and Integration: This layer stores data and integrates with various services and components to form the storage foundation. Apache Hadoop HDFS, Ceph and the likes can be utilized here. The almost-unlimited storage capabilities of Cloud can be integrated here of course.
Data Analysis and Consumer Interface: Apache Superset or Apache Zeppelin can be used to analyze the data and generate insights and reports. The data is made accessible through various data visualization and reporting tools, as well as through APIs and data streaming technologies.
Metadata Governance: Apache Atlas or LinkedIn Datahub can be used to implement metadata governance in the data platform architecture. It is responsible for controlling the accuracy, completeness, and consistency of metadata, and ensuring that metadata is stored and managed in a centralized repository.
Data Pipeline: Apache Airflow can be used to manage the data pipeline. It is responsible for scheduling, executing, and monitoring data processing tasks. The pipeline ensures that data is processed and delivered in a timely and accurate manner.
With open-source tools, building a lean and scalable data platform is within reach. Embrace the limitless potential of open-source software and join the ever-growing communities to bring your data platform to the next level. Happy building!
Lets say you have a lot of data and you have a team of data scientists working very hard on their AI/ML initiatives to get valuable insights out of the data in order to help driving your business decisions. You want to offer your data scientists the same experience that software developers have in a native cloud environment where they enjoy the flexibility, scalability and tons of other cloud advantages to get their things done faster?
Lots of options available nowadays, and this post walks you through 1 of them using OpenShift 4 and Red Hat Open Data Hub
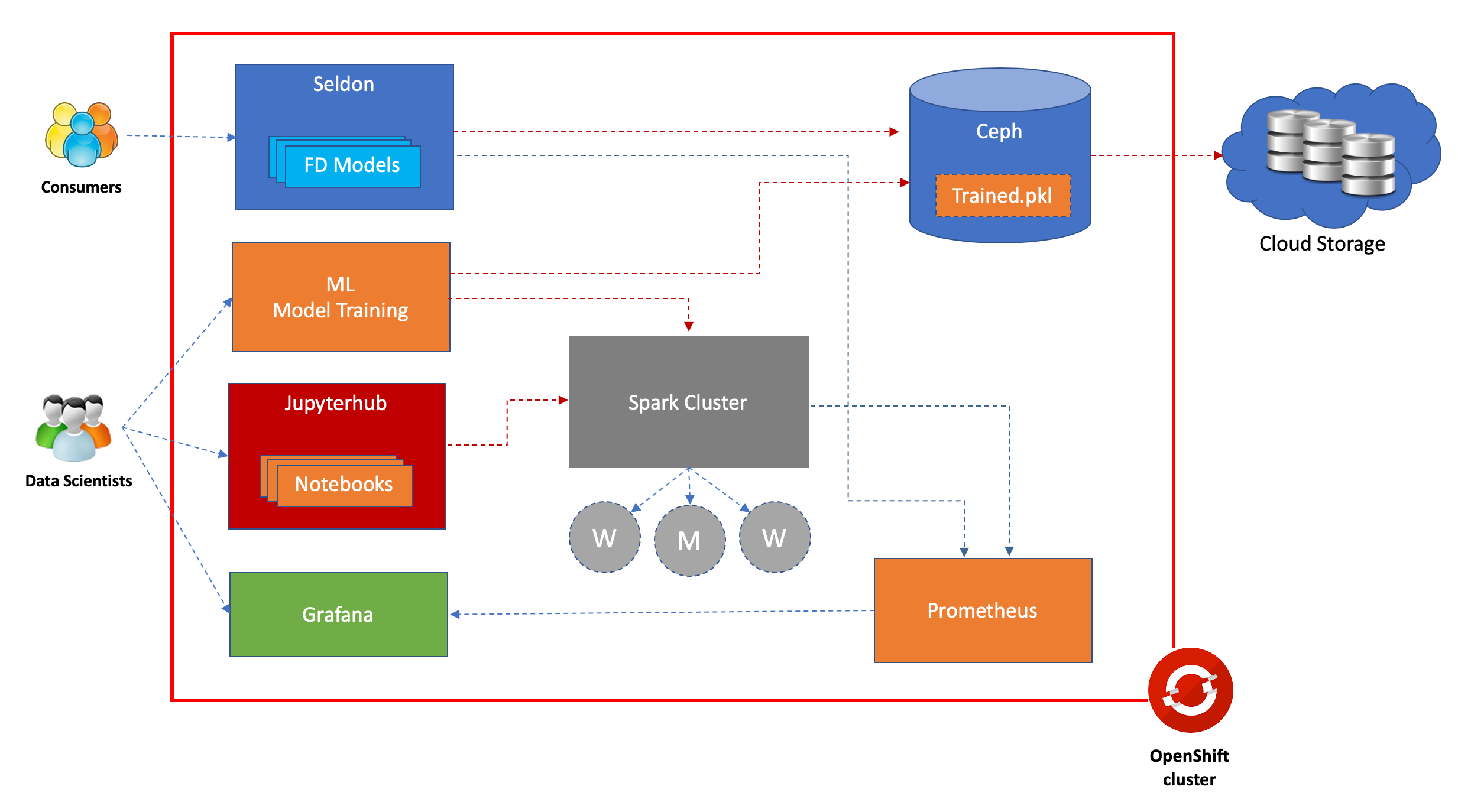
Architecture over view of the example:
Architecture overview of the setup
Data exploration and model development can be performed in Jupyter notebooks using Spark for ETL and different ML frameworks for exploring model options After data exploration and algorithm, model selection, the training activities can be fully performed and resulting trained artifacts can be saved into Ceph
Once the model is available on Ceph, Seldon will help to extract it and serve end consumers
All model development lifecyle can be automated by utilizing variety of available tools or frameworks in Red Hat ecosystem.
Performance of the models can be monitored using Prometheus and Grafana
Prerequisites:
An Open Shift cluster
oc cli client
git client
Steps to spin up your environment
Installing Object Storage
We use Rook operator to install Ceph. Make sure you have cluster’s admin credentials
Clone this git repository
$ git clone https://github.com/dnguyenv/aiops-pipeline.git
$ cd aiops-pipeline/scripts
scripts folder contains scripts and configuration to install the open data hub operator. These environment variables need to be set before running the commands:
oc expose service rook-ceph-rgw-my-store -l name=my-route --name=spiritedengineering -n rook-ceph
Install the ML pipeline components
Create a new project to contain the pipeline components
oc new-project demo
In order to access the Ceph cluster from other namespace, will need to copy the secret to whichever namespace is running the applications you want to
interact with the object store
For example, you want to use it from demo namespace:
Before running the installation script, make changes to scripts/deploy/crds/aiops_odh_cr.yaml accordingly to to enable/disable pipeline components as needed.
Deploy the Open data hub custom resource
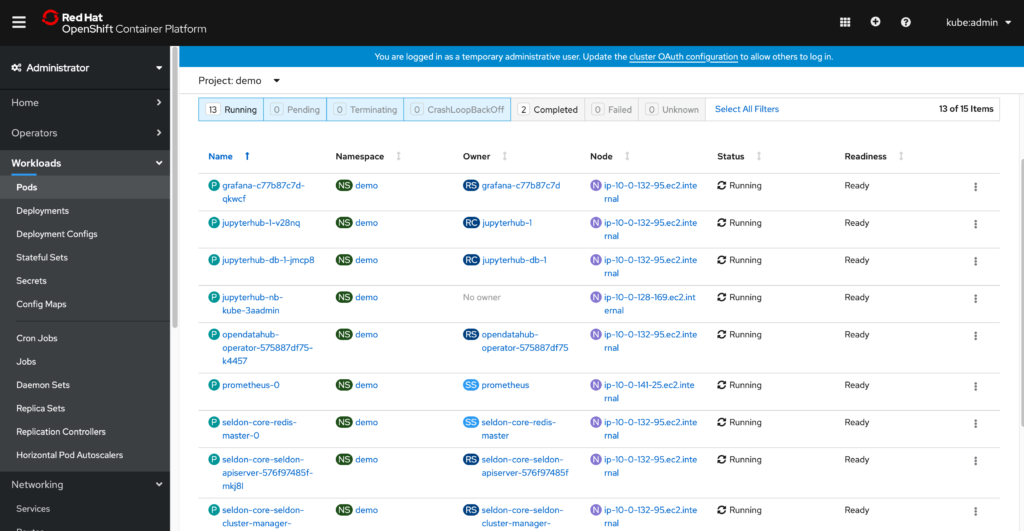
Now you are good to utilize the infrastructure as the development environment for your ML initiatives
All ML platform components are running as Kubernetes objects
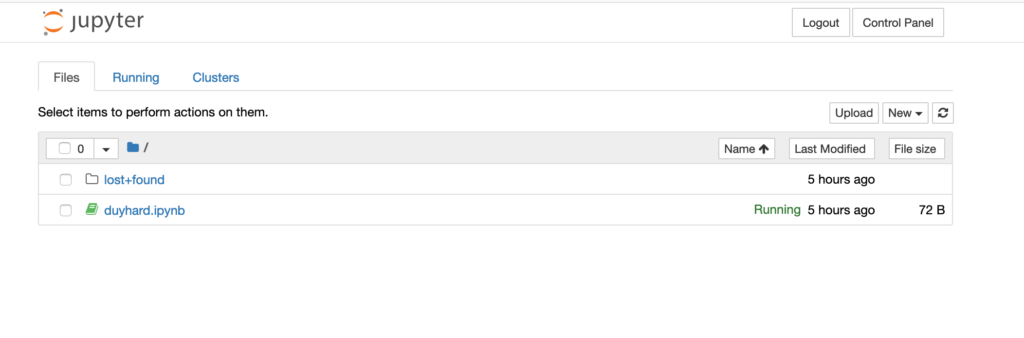
To access the Jupyterhub and work with your notebooks, you will need to know its endpoint. That can be done by
oc get routes -n demo
And grasp the HOST/PORT value in the returned list accordingly to the jupyterhub route
Jupyterhub
Using that endpoint, you can spawn up a Spark cluster to use for your ML initiatives. Each user will have a dedicated cluster launched as a set of container.
Once the user logs out, the cluster will be terminated.